RNG does not collect any personal information.
RNG does not use or share your personal information.
Non-personal data like statistics about the number of app downloads may be collected by Google.
Author: Frank Forte
-
RNG Privacy Policy
-
Letters Game Privacy Policy
The letters game does not collect any personal information.
The letters game does not use or share your personal information.
Non-personal data like statistics about the number of app downloads may be collected by Google.The Letters Game was created as a hobby project to help young children learn to read with their parents.
-
ChromePhp / FirePHP alternative for Firefox Quantum: server log to the developer console
This week, Firefox 57 (Firefox Quantum) was released (2017-11-15). It was a breath of fresh air. It felt more than twice as fast. I was ready for a productive day.
That first breath was so nice that I inhaled again, but this time is didn’t smell so sweet. It was like walking around in downtown Toronto. You could smell something awesome one moment, then when you try to get another whiff, you smell something pungent.
TL;DR, server logs from ChromePhp stopped working, so I rolled a new version: QuantumPHP on GitHub
Within minutes, I noticed two things that I didn’t like.
1) When the MS Windows hosts file is updated (for example, to point a domain to our QA servers), the browser continues to point traffic to the previous IP address. Shift refresh will send traffic to the correct IP, where I am able to add an SSL exception for the QA server. However, subsequent requests continue to go to the old ip address. Flush DNS and renew DNS did not help.
2) Server logs were removed. All that helpful information sent back via ChromePHP just stopped working.
Now, #1 is nothing new. Firefox likes to cache the ip address for domain names, and it does not like to update that cached information. I was just hoping that this new version would be a bit smarter about updating this type of cached information, especially after the Dyn DNS attack last year.
On the other hand, #2 was a surprise. I thought that maybe I just needed to turn it on somewhere, but a Google search revealed this statement by Nicolas Chevobbe:
Server logs are no longer supported natively since there are no parts of the ConsoleAPI specification and there is a webextension to make them available.
I could not find the "webextension" that Nicolas mentioned, so I created QuantumPHP to get my server side logs showing up again. So I rolled my own one of those too: QuantumPHP add-on for Firefox . If you don’t want to use the add-on, you can manually add the JavaScript file, QuantumPHP.js, to your web page HTML to make it work.
I hope it can serve a lot of the ChromePHP and former FirePHP users.
I added some big improvements on ChromePHP, notably:
A) comments can be easily added in your PHP script, and the output in the developer tools console will be a table, including the time, file and line number where the comment was added.
B) You can set a maximum header size, so that Apache does not throw up and show a 503 page when you send a header above 8MB. QuantumPHP will truncate your log and warn you.
C) Firefox now handles tables in the console log infinitely better. Objects and arrays can be expanded easily to view deep properties, and the column widths can be properly resized (they also stretch when the browser window stretches). This was not the case in the previous version.
In case you are wondering why I don’t just use Chrome for development, it is because the issues there were more serious than the issues in Firefox. For example, it seems to choke on medium to large logs (where the HTTP response header size is relatively large). The console simply does not display the logs.
It was not fun coming into work and realizing that one of my important tools was broken. But now I have a new tool, and I like it better.
-
Forte Specialization: Machine learning
Abstract
This article discusses a potential method to increase the efficiency of a neural network in processing information. More specifically, the use of synaptic plasticity in order to optimize data flows between neurons in a convolutional neural network.Introduction
When building a convolutional neural network for machine learning, it is common to hard code linkages between neurons, where data is passed through each layer of neurons, and back propagation is used to help each layer in the network learn the weights that should be assigned to each input feature so as to predict a more accurate outcome.1Choosing the number of neurons and layers in a neural network could have some effect, however, it might be more effective to allow each neuron to independently determine the priority of each input. More specifically – if more than one input provides the same information, it could choose the input that provides the information first (be more sensitive to that input from the previous layer), and give a lower priority to the slower input (using neural fatigue, in a sense). The priority given to each input can determine the strength of the linkage between the neuron and its input. If the strength is below a certain threshold, the linkage can be severed, and thus, less data must be processed by the individual neuron. In fact, this could lead to “specialization”, where certain neurons that are closer to specific stimuli (types of data) become better at “knowing” about that data. This is similar to the way parts of our brains can be trained to interpret audio or visual information.
This concept may give a turbo boost to parallel processing. Each process can be fine tuned to get excited by specific “frequencies” of data.Methods
Each neuron would keep track of each input. When an event occurs (for example, data from an image is sent for processing) the neuron would assign the input values to the appropriate inputs with a time stamp. It could then compare inputs, and assign a priority to inputs based on how unique their information is, and how quickly the information was received.
Should an input’s priority fall below a specified threshold, the neuron could send a “slow down” or “terminate” signal to the input, telling it to send data at a lower frequency or to stop sending data altogether.If an input neuron no longer has any upstream link, it can effectively die, and send a terminate signal back to all of it’s own inputs.
Should the priority of many inputs be high on the other hand, the neuron might consider making new linkages with the next layer of neurons, since it is receiving a lot of high priority signals.Keep in mind that the priority is independent of the weights of features that are being learned. The point of “Forte Specialization” is not to determine which features are important, but rather, which inputs are important.
Results and Discussion
If and when I get around to it, I intend on implementing the above logic by writing code and running some tests and benchmarks to see what we might learn. If you are interested in collaborating with me, please get in touch.Works Cited
Aside from the concepts related to neural plasticity and input priority, credit goes to Geoffrey Hinton of the University of Toronto and Andrew Ng of Stanford who both published excellent machine learning courses online, describing neural networks and their implementations.
Copyright 2017 Frank Forte. All rights reserved. Unauthorized reproduction of this work are prohibited.
-
Un-hackable customer data: how Equifax can prevent future hacks

Image courtesy of Pexels
Keep your customer’s data secure. It’s your responsibility. You ask for that data, you specifically require it from your customers to process credit checks. So, keep their data safe.Equifax could have done many, many things to protect customer data. This post is about one of those things, storing data in an un-hackable way.
Anyone who writes code will at some point learn about hashes. There are ways to use hashes of customer data instead of the customer data itself to meet business requirements.
A hash is a scrambled string of characters, for example,3c1fd1b2c915eacf, that is created by taking a piece of data such as a social security number, SIN or date of birth, and using a cryptographic algorithm to scramble that data in a repeatable way.
The great part about hashes is that they are searchable. You can store a hashed version of someone’s name, SIN number, or other sensitive or personally identifiable information (PII), and you can find that user’s record by typing in the original data when required, which can be hashed with a program, then the database can be searched for a matching hash. Even better? They are un-hackable. Even if a hacker steals this data, it is meaningless and has no value, what are they going to do with “3c1fd1b2c915eacf”?
What about data that you need to send to third parties? You need the original data in some cases. You can link the hashed records with an encrypted record that only contains the bare minimum information needed to conduct business. The hash search can pull up that encrypted data, then the data can be decrypted and sent back to authorized employees or third parties over an encrypted connection, like https.
Now that you have an idea of what is possible, how should we apply this knowledge?
Organizations need a policy for classifying data.
More specifically, determine how each field is used and how each should be stored:
A) required for search (hash)
B) required for validating correct information supplied (hash)
C) required by an outside party (encrypt)
D) required for Analytics or statistics? Ideally do not include PII and do not link it to the original records, so that data still provides insight, but it is anonymous, so hackers still find very little value in stealing the data, and liability is very limited.
E) how long is each field required? Delete data once it’s useful life is over. You would be surprised how much data can be deleted almost immediately with minimal impact on operations. This minimizes the amount of information exposed if and when a hack does happen.
Once customers give you their data, they don’t have control of that data anymore, so they rely on you to keep it safe! Be smart, invest in better data storage and retention policies.
If you need a consultant on preventing hacks in your organization, contact me. If you you are a software developer just stopping by to learn more, please make sure you research why you need to add a “salt” to your hashes, and use up to date hashing algorithms like sha256.
Thanks for your interest!
Copyright 2017. Frank Forte. Unauthorized reproduction of this work is prohibited.
-
502 / 400 Error in Apache when using Firebug or ChromePHP
It turns out that Apache will return an HTTP error (usually 502) when headers are larger than 8KB. This is much like the White Page Of Death since there is no indication of why the page failed to load.
I developed a fork for ChromePHP that allows you to shrink the ChromePHP debug log so that it prevents the Apache error:
https://github.com/frankforte/chromephpIt shrinks the log by removing notices first, then warnings or errors.
-
Quantum Superposition
If you have an interest in quantum physics, you might have tried to wrap your head around the fact that particles like photons can be in more than one place at the same time.
I believe the strange quantum effects of superposition have to do with the object changing states.
In the double slit experiment, it has been shown by firing a single electron or photon at a time, the interference pattern still appears.This means it is in more than one place at a time.
If there are no other photons fired at the same time, why does the photon not act like a particle and go straight through one of the slits onto the screen/detector? Why is there any probability of the particle flying off one way or the other?
Take a look at this video of superposition:
https://youtu.be/DfPeprQ7oGcWhile the photon is traveling, I would argue that it is literally a wave, a perturbation of space time, energy traveling through a field, just like sound waves or waves traveling through water. When passing the double slits, it does pass through both slits at the same time, causing interference with itself, and creating a probability that the photon will collapse in an “unexpected” position (unexpected, if you expect it to always act like a particle).
I would say that there is no particle in two places at the same time. This is because in a state of superposition, it is not a particle, but a wave of energy. It needs to “collapse” into an object in order to interact (in order for you to observe it) but until it does, it can be considered in more than one place at a time… as a wave that is traveling through space-time if you will.
Another way to visualize it (as I do) is that a photon is like a liquid, it can coat a surface until it crystalizes or condenses into one point.
Consider the following article about photosynthesis. They argue that the photon checks all paths at once and chooses the most efficient one:
http://m.livescience.com/37746-plants-use-quantum-physics.html
This argument, and the basis of quantum computing are consistent with the particles literally being in more than one place at a time, and, to use my own words, they condense or crystallize in the most efficient location (which should correspond with the mathematical probabilities given by the Schrödinger equation).
Here is an analogy. If you stretch a drop of water into a thin layer on a substrate, it will bead up into a ball (this is the most efficient shape because it minimizes surface area and lowers the surface energy, assuming the substrate is hydrophobic). You can think of “more than one place” as the area of the substrate that is coated just before the water beads up into a ball and ends up “in a single place”. The probability is most likely that the droplet of water will end up in the middle of the area it was covering, but there is a small probability that it will end up towards one of the edges. Further, if there is a spec of dust for the water to “grab onto”, it’s final location will depend on the location of that spec. It found the most efficient location instantly, because it “knew” where the spec of dust was before it took it’s final, spherical shape and location. The bead of water was never in more than one location at a time, but the water was.
Now the act of observing disturbs the photon or electron enough that it “beads up” into one location, so it’s state is changed and it is no longer able to be in more than one place at a time.
-
How to atomatically start an app pool in Windows IIS when it crashes or stops
I have had the problem of a production website going down and giving a 503 error every couple of months, and it turns out the application pool in IIS was just stopped and decided not to restart.
The website is on windows server 2008, and the website runs PHP (the problem occurred with every PHP version we have run).
I found that in the IIS gui, you can click the problematic app pool, go to advanced settings, and under Rapid Fail Protection, you can add a program to run when the pool is shutting down.
Shutdown Executable: c:\Windows\System32\inetsrv\Appcmd.exe
Shutdown Executable Parameters: start apppool /apppool.name:”nameOfYourPool”I know running the above from the command line works. Let’s hope it works the next time the app pool crashes or turns off unexpectedly.
-
Why You Shouldn’t Re-use Passwords
Unfortunately, many people don’t realize that re-using passwords is kind of like using the same key for your house, car, safety deposit box, gym locker and bike lock, and then sharing that key with a number of people you don’t really know. Even if those people seem trustworthy, a few of them might not take the same steps to protect that key. They might even put your name and address on it and leave it in plain sight for their own convenience… to keep track of who’s keys they are borrowing.
When you re-use a password on a new website, you are essentially sharing your key with a person (or number of people) that you don’t really know. Unlike a physical key that protects your physical possessions, passwords protect your online identity. In the wrong hands, they can be used to steal your identity, whether they break into your accounts and steal directly from you, or create false accounts to “borrow” money or buy things in your name, things that people will expect you to re-pay. Unlike a physical key, many hackers from many different countries can steal and create copies of your login information without you knowing it (there is no hint that someone stole it.. unlike a physical key where you would at least notice if it was “missing”).
Hackers know that many people re-use passwords. When they break into a website with little or no security, they will use the emails and passwords they find and attempt to access other websites with those same credentials. If you don’t re-use passwords, congratulations, you may have just saved your online identity and prevented a lot of pain and suffering.
Now that I convinced you to start using different passwords for different websites, let me include a comic I found that will help you come up with easy to remember, hard to crack passwords:
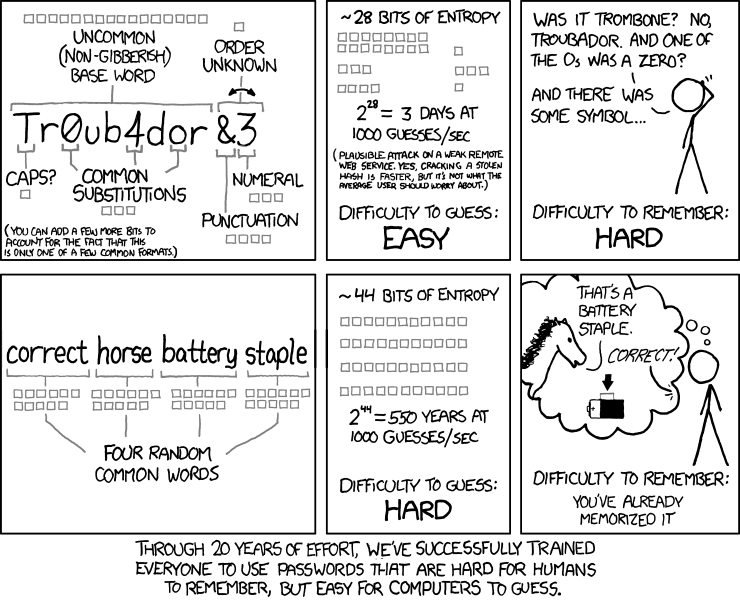
If you manage or develop a website, see this related article: Protecting User Accounts – Password Management
-
Protecting User Accounts – Password Management
If you develop or manage a website, there are many reasons to take time and protect user data. Consider if your website is hacked:
- In the case of eCommerce, fraud can be costly to the user and to the website owner.
- It can cause privacy concerns and damage your brand.
- It can allow hackers to spread viruses, send spam, and do a lot more damage through your website over long periods of time without you even knowing it.
- You can be black-listed by search engines and email providers… making your website hard to find and preventing your emails from reaching any users.
Here are some tips to protect user accounts
To store user passwords:
The Password-Based Key Derivation Function, aka PBKDF2, allows you to store passwords securely, so that even if someone hacks into your database, it will be very difficult and time consuming for them to crack and steal passwords. This is important since many people re-use passwords!To reset user passwords:
1) create a table with user_id, datetime, unique_hash
2) When a user requests to reset their password, create a unique hash, for example sha1(microtime().’random_salt’). Insert that value in the table and send an email to the user with a link that contains the hash.
3) when they click the link, check the table for the hash, if it exists, and it is within a time limit (e.g. 3 hours) let them reset their password. When the password is successfully reset, delete the hash.To authenticate:
1) have a “password attempts” field that increments each time a login fails. If there are too many attempts (e.g. 10), even the right password should fail.
2) if there is a successful login (only before 10 attempts is reached) then the attempts should be set back to zero (this is also a good time to log the website access, including ip address, time, and user id- keeping track of website access is important in case an account is compromised.)
3) Once locked out, the only way to regain access should be with a password reset, usually done through email.
The above authentication logic thwarts brute force attacks. Even if a computer can try millions of passwords and guess the correct one, by the 11th attempt it will be locked out.